FileMakerのカスタム関数は、利用することはあっても、自ら作るという機会はそれほどないのではないでしょうか(自分がそう)。今回の記事を読んでみれば、その手法を採用するかどうかに関わらず、カスタム関数の書き方について考えるきっかけになるかも知れません。
![]()
A Variable Way of Writing Recursion
(元記事はこちら)
Daniel Wood
2019/3/22
はじめに
再帰(recursion)は、FileMaker開発の中では多くの人にとって厄介な部類に入るでしょう。熟練の開発者であっても、それがどのように機能するか理解するのに苦労することがあります。FileMaker認定資格試験を受けたことがある人に聞いてみるとそれがよくわかるでしょう。
この記事では、まず単純な例を使って再帰とは何かについて簡単に紹介したあとで、この記事を書いた主な目的である、より単純で理解しやすい簡単なカスタム関数を作成する代替案を提示します。再帰とは何か、どのように機能するのかをすでに理解している方は、この導入部を飛ばして、より面白い本論部分に進んでください。それ以外の方は以下の再帰入門を楽しんでください 🙂
では始めましょう!
再帰とは、実際には単なるループ
一言で言うとそういうことです。計算で必要な場合に、再帰を使ってループ構造をシミュレートします。FileMakerには現時点ではループ関数がないため、同じ効果を得るために再帰に依存することになります。これはFileMakerスクリプトのloopの出来の悪い兄弟だとも言えます。スクリプトのloopでは、繰り返しの中でレコードや変数の値を使ったり操作することができます。再帰関数は通常、値のリストをループしながら操作するために使われます。値を変換したり、値のリストを作成するためにも使用できます。
もちろん、それらは他の用途にも使われますが、FileMakerの開発で使うほとんどの再帰関数は、リストのような複数の値の処理をおこないます。
再帰関数を書くにはカスタム関数を使う
FileMakerでは、「カスタム関数」の機能を使って再帰的なカスタマイズされた関数を作成します。カスタム関数とは、あなたが自由に宣言して自分で書くことができる関数です。それらは再帰的である必要はありませんが、その自由度の中で、必要なら再帰的に書くことが簡単にできます。
FileMakerのメニューでは、[ファイル] – [管理] – [カスタム関数]からアクセスします。
カスタム関数を書く
FileMaker Pro 16以前では、この機能はFileMaker Pro Advancedのユーザだけが利用できました。FileMaker Proではカスタム機能を利用することはできましたが、作成することはできませんでした。FileMaker Pro 17のリリースによって、Advancedという別のバージョンはなくなりました。したがって、FileMaker Proを使用してこれらの機能を記述できます。そのためにはFileMaker Proの環境設定で、”Use Advanced Tools”オプションを有効にしてください。
再帰がループに似ているということはわかりました…でも、どういうふうに?
Techterms.comに再帰についてのわかりやすい定義があります。
再帰とは、関数が自分自身をサブルーチンとして呼び出すプロセスのことである。この関数は実行中に自分自身を呼び出すので、関数を複数回繰り返すことができる。再帰を組み込んだ関数を再帰関数という。
ここで重要なのは、関数が自分自身を呼び出すという部分です。関数が自分自身を再び呼び出すたびに、次に進むと考えることができます。あるいはスクリプトのloopのアナロジーで言うと、次のレコードに移動するのに似ています。10項目のリストをループしてそれぞれに何かをしたい場合、関数は自分自身を9回呼び出します(初回はユーザが呼び出し、残りの9回は関数が自分自身を呼び出す)。
もう1つの見方としては、ドロステ効果のように考えることができます。以下のような写真を見たことがあると思いますが、これが再帰について考えるのに適しています。ドロステ効果についてはここに詳しい説明があります。

再帰の簡単な例
ここに単純な関数 _factorial (_integer) があります。
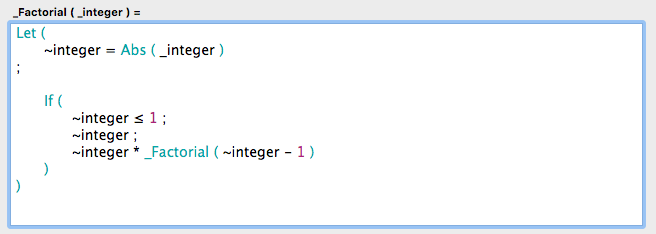
この関数に数値が渡されると、その整数とそれより小さいすべての整数(最後は1)の積を返します。例えば _factorial (4) は結果として24を返します。これは 4 * 3 * 2 * 1 を掛けることで求められます。
この関数は、最初に引数を取りそれを絶対値にします。これは純粋に引数が負の数にならないようにするためです。
再帰関数には終了条件があります。これは再帰が終了するのか継続するのかを判断するためのチェックで、”Exit loop If”スクリプトステップとまったく同じです。
関数が呼び出されるたびに、次の1小さい整数が渡されます。終了条件は、1が渡されたときです。
まだ値 “1”が渡されていない場合、この関数は、渡された整数に、再度呼び出された関数(引数は1小さい整数)の結果を乗算します。
まだ理解できていない場合は、以下の図を見てください。
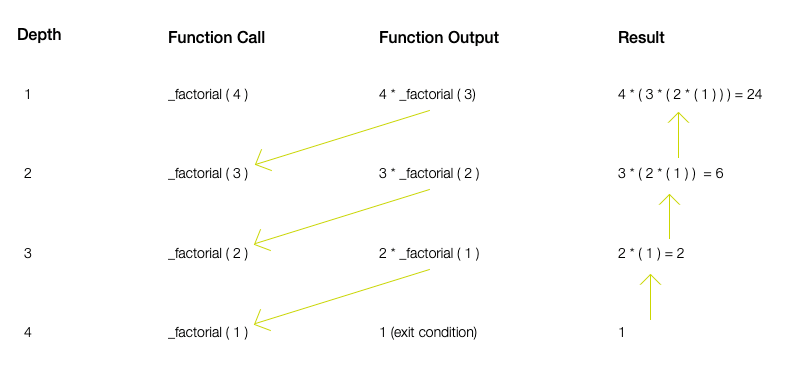
ここでは、各行をそれに続く関数の再帰呼び出しとして示しています。この関数が最初に呼び出されたときには、値4が渡されます。終了条件 “4は1に等しいか?”がチェックされます。答えはfalseなので、4に再帰呼び出しの結果を乗算します。次にこれを、引数を3として繰り返します。これは2行目に示されています。終了条件を再度チェックしますが答えはまだfalseです。したがって、この呼び出しの結果は、3に、引数を2とした関数呼び出しを掛けたものになります。
さらにこれを、終了条件”1は1と等しいか?”がtrueになる4行目まで繰り返します。これの結果は単に1を返すことです。
結果の1は3行目に戻され結果として使用されます。3行目は 2 * 3 になり、これが2行目に渡されます。
2行目の結果は 3 * 2 * 1 です。これが最初の行に戻されます。
これをResult列で見ることができますが、それぞれの関数呼び出しの結果は元の関数呼び出しに再帰的なチェーンの繋がりを介して渡され、そこでようやく完全に結果を評価することができます。
わけが分からないですか? 大丈夫です。まだ理解に苦しんでいるなら、まずはこの記事のサンプルファイルをダウンロードすることをお勧めします。記事の末尾にリンクがあります。サンプルファイルには、再帰関数を理解するための、イラスト付きのステップガイドが含まれています。設計情報にアクセスできるので、自分自身で関数を見て、そのしくみを理解することもできます。
変数を使って改良する
ここまで見てきたように、再帰が行われる最も一般的な手順は、各反復で値を処理してから、変更後の引数を次の再帰呼び出しに渡すというものです。これは通常、リストから要素を削除するか、または各再帰ステップが今リスト内のどの位置を処理しているかを認識できるように、再呼び出しごとに増分されるカウンタ引数を維持することによって行われます。
リストの変更(値の切り捨てや左右からの値の取得など)は、何百回も行われると、非常にコストが高く時間のかかる操作になる可能性があります。理想的には、使用する引数を変更しない状態に保ち、カウンタを使用して反復内の位置を参照したいところです。その方がはるかに効率的に処理できます。
しかし、もしカウンタを引数として渡したくないとしたら、どうすればいいのでしょうか? カウンタとしてローカル変数を使用できるでしょうか? さらに、読みやすさと関数の単純さを向上させるために、ローカル変数をどの程度まで使うことができるでしょうか? 結論としては、かなりの程度まで使うことができます。
ポイント – 変数は1つの再帰呼び出しから次の呼び出しへ進むときに保持される
そのとおりです。ローカル変数は1回の再帰呼び出しで定義でき、その値は後続のすべての再帰呼び出しからアクセス可能になります。これにより、関数の引数を使用せずに、1つの呼び出しから次の呼び出しに情報を転送するのが非常に簡単になります。これは、機能全体を通して参照するために情報を入れることができる記憶領域と考えることができます。
そこでこの事実を利用して、より複雑な関数を書くための代替案を示します。
ただし、ここで紹介する手法が最善ではない場合もあることに注意してください。再帰が十分に単純な場合は、従来の最も簡単な方法で記述したほうがいいでしょう。変数を使用することは、他の開発者の読みやすさを向上させるための良いテクニックであり、最小限のリスト操作関数を通してパフォーマンスを向上させることができますが、最終的にはあなたにとって最もうまくいくものを選択してください。
例: _RemoveValues関数
(この記事に記載したすべての例は、リンクからダウンロードできるサンプルファイルに含まれています。)
もう少し頑張りましょう。この関数は次のように定義されます。
_RemoveValues ( _listA ; _listB )
引数として2つの改行区切りリストを取り、_listBに存在しない _listA内のすべての値を返します。
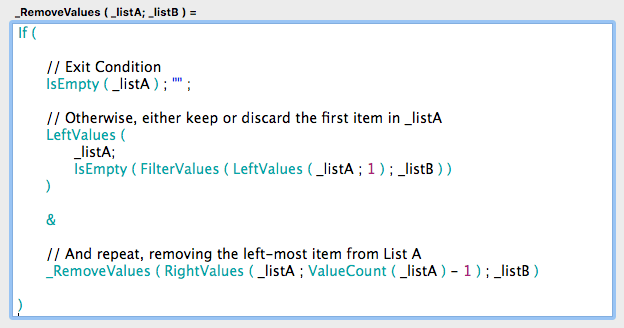
この関数の書き方は、多くの再帰関数に見られるかなり典型的なスタイルです。まず終了条件から始まり、それは”最初のリストが空”の場合です。
処理対象の_listAに値がある場合、そのリストの最初の値が_listBにあるかどうかチェックします。もしあればそれを保持し、なければそれを破棄します。これは、_listAの左から1番目の値、または0番目の値(つまり空)のいずれかを取得することによって行われます。
その値に再帰呼び出しの結果を追加します。ただし、この呼び出しの引数は、一番左の値がない(たった今処理した)_listAです。
ここで、2つのかなりコストの高い関数であるLeftValuesとRightValuesを使用しています。大きなリストを扱うときには、これらは非効率的な関数です。_listAに項目が1,000個ある場合を考えてみましょう。1,000回の再帰呼び出しが発生し、そのたびにRightValues関数を実行して左端の値を取り除くことになりますが、これはかなりの数です。
変数で書き換える
以下に示すのは同じ関数を別のアプローチで書いたものですが、ここではローカル関数と、関数構造に対する標準化されたアプローチを使用しています。
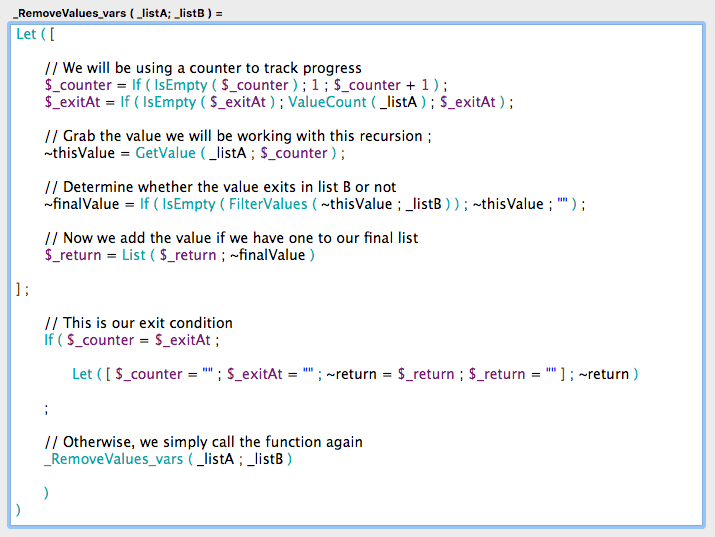
ここで、説明が必要なかなり多くのことが起こっています。最初に気がつくのは、コメント行を含まないとしても、コード行が増えていることです。コード行は多いですが、それは実際には全体的により読みやすい関数を作るためであり、そして再帰について考えるためのより単純化されたアプローチを実現するためのものです。このアプローチはスクリプトのloopに似ていて、再帰呼び出しの複雑な特性について考える必要はありません。
構造として、この関数は以下の標準に従う形で書かれています。
- カウンタと終了値を定義する
- 定義する変数(ローカル変数またはLetステートメント内)の数にかかわらず、明確で読みやすくする
- 最終結果の値を保持するためにローカル変数を使用する
- 終了条件を定義する。trueと評価されたら、使用しているすべてのローカル変数をクリアし、結果値を返す
- 終了条件が満たされない場合は、同じ引数を使用して関数をもう一度呼び出す
この手法と標準的な再帰処理の主な違いは、渡された引数を再帰呼び出しのために更新する必要がないことです。それらは全く同じままです。修正の必要はありません。カウンタ用引数も、ローカル変数に保持されるので、不要です。
終了条件と変数について
終了条件に到達したら、すべてのローカル変数を消去することを強くお勧めします。そうしないと、関数の終了後にそれらの値がデータビューアに残ります。この状態は0 script stateとして知られ、スクリプトのスコープ外(例えば今回のような関数の中)で定義されたローカル変数が存在する可能性がある状態です。環境を汚さないよう、処理が終わったらそれらをクリアします。関数内で定義するすべての変数にアンダースコアを付ける理由の1つは、それらが関数から定義されたことを識別するためです。通常のスクリプトで変数を定義する場合は、アンダースコアを付けて定義しないようにしてください。これは、関数内で定義された、クリアされない可能性がある変数と、スクリプト内で定義された変数が衝突することがないことを保証するための、もう1つの手段です。
カウンタと終了値を定義する
関数の最初のステップは、カウンタと終了値を設定することです。再帰での位置を追跡するために、関数が呼び出されるたびにカウンタが1増加します。終了カウンタ値は、処理をいつ停止するかを示します。通常これは、処理前のリストのサイズと一致するため、開始前にわかります。

最初のチェックは、カウンタ値があるかどうかです。これが、関数が最初に呼び出されるときに初期カウンタ値に1を設定することを保証します。それ以降は各再帰呼び出しがカウンタ値を見て、初期化する代わりに1増分します。
終了値の変数についても同じです。最初の呼び出しでは空なので、listAのサイズに設定します。それ以降の呼び出しでは変更しません。この値は一度設定されるだけです。
処理対象の変数の定義
処理対象の変数は、1つの再帰呼び出しから次の呼び出しに渡す値を格納するのに使われます。これにはローカル変数を使います。1つの呼び出しから次の呼び出しに渡す必要がない変数の場合は、代わりにLet文の変数を使用します。そのスコープは現在の関数呼び出し内のみです。

この例では、連続した各関数呼び出しがリスト内の特定の値を対象にします。カウンタでその値がわかり、GetValueで取得できます。GetValueはLeft/RightValuesと比較するとはるかに効率のいい関数です。
値が_ListBにあるかどうかを、前の関数定義で行ったのと同じ方法で、確認します。
最後は結果変数$_returnです。これに最終結果を格納します。この値は、1つの関数呼び出しから次の関数呼び出しに渡されてからも持続します。
終了条件
以下が終了条件です。

終了条件はほとんどいつも同じで、カウンタが終了値に達したときです。この時点でいくつかすることがあります。
- ローカル変数の値を消去する
- 戻り値をLet内の変数に格納する
- 戻り値を保持する変数をクリアする
- 結果を返す
ステップ2と3は少し特殊です。結果はローカル変数に格納されますが、結果として返す前にこの変数をクリアすることはできません。これを回避するために、Let内の変数に格納して代わりにそれを返します。関数が終了すると、Let文の変数は自動的にクリアされます。Let関数を使用すると、使用したすべての変数を簡潔に消去できます。
そして最後に、再帰呼び出し
私たちの再帰関数の定義では、再帰の実際の動作は単なる付け足し的な位置付けになります。それについて考えたり、何を渡すかを心配したりする必要はありません。単にそれを呼ぶだけです。

この手法の長所と短所
前述のように、これは再帰的なカスタム関数を作成するための別のアプローチですが、正しい手法とは見なされません。ですが、あなたが望む方法で書くことに何の問題もありません。この手法を使用することには長所と短所があります。長所は次のとおりです。
- 読みやすさの向上 – 他の開発者があなたのコードを解釈しなければいけない場合に便利
- スクリプトのloopに似たシンプルさ
- 後続の呼び出しに渡す引数を変更する必要がない
- カウンタなど状態を追跡する引数は不要(変数が代替)
- 理解するのが簡単
一方いくつかの短所があります。
- 終了時に変数をクリアする必要がある
- 変数がクリアされていないと他のプロセスに干渉するリスクがある
- FileMakerがサポートする機能であることを保証するものではなく、将来的に廃止されないことを保証するものでもない
- 純粋なLet文とは異なり、ローカル変数を使用することでパフォーマンスに影響を受ける可能性がある
- 再帰的関数が各呼び出しで自分自身を複数回呼び出す場合、うまく動作しないかもしれない(例えば、一部のソート関数)
選択するのはあなたです。あなたにとってうまく機能するなら、この手法を受け入れて利用してください。私たちはそうしました。しかし、すべての関数が同じというわけではなく、別のアプローチの方があなたにとってよりうまくいくかもしれません。我々がこの記事を書いた目的は、この手法が読みやすく簡単に理解できることから、開発者が複雑な再帰的カスタム関数を書くことに対する不安を払拭するのに役立つことです。
サンプルファイル
他のすべての記事と同じように、今回も詳細なサンプルファイルを用意しています。説明を読むだけでは不十分です。以下のサンプルファイルを参照して、実際に動作するところを見て、自分自身で仕組みをさぐってください。