Dr. Ray Cologonは、FileMaker Pro Bible 9, 10の著者で、英語圏のコミュニティで多大な影響力を持つ、FileMaker開発の第一人者です。
彼がDirector of Developmentを務めるNightWing Enterprisesのサイトでは、FileMakerの可能性を示すための機能デモ用のサンプルファイルが、.fp5の時代から定期的に公開されています。
今回は、2014年にVer.13のリリースに合わせて公開された13のサンプルファイルのうち、FileMakerの特性を活かしながら大規模なシステムでも活用できるprocessing in placeというコンセプトのデモを紹介します。

Duplicate Hierarchy v2.0
このデモで示そうとしたコンセプトが3つあります。1つは自明ですが、残りの2つは少しわかりにくいかもしれません。
まずタイトルが示すように、このサンプルはネストされたレコードセット(階層化された木構造で、深さや複雑さが事前に決まっていないもの)を自動的に複製する方法を説明しています。詳細に見ていくと、これを実現するためにはいくつもの課題を解決しなくてはいけないことがわかります。単一レコードの複製は、誰でもわかります。任意の子レコードのセットと一緒に、その共通の親レコードを複製するのは、多少難易度が上がります。子レコードのかたまり(枝)が複数あって、それぞれの子レコードが1つ以上の枝を持つ場合に、それらの構造を再現しながら一つずつ複製するとなると、これは業務用途並みの難題になります。
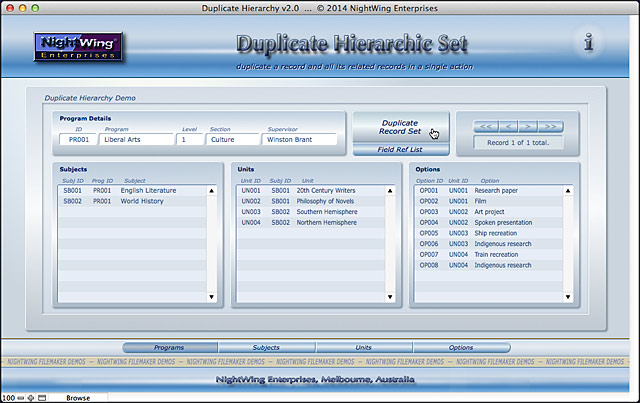
このデモでは、2つのプロセスを組み合わせることで、そのような規模の大きい課題を解決します。1つ目のプロセスは、FileMakerのデザイン関数を応用して、現在のユーザ(レイアウト)のコンテキストから放射状につながるすべての結合(join)の位置関係を再帰的にすべて解析します。対象は、現在のレコードに関連するレコードを持っている可能性のあるすべての結合です。2つ目のプロセスは、1つ目のプロセスで取得された位置関係の情報を受け取り、それをたどりながらレコードセット全体にわたって、関連レコード一つ一つの場所を(階層の深さに関係なく)特定し、再作成し、再結合していきます。その結果として、現在のレコードとその子レコード(孫、ひ孫、…を含む)のセットを元にした、完全で自己完結的な構造のリレーショナルなデータセットのコピーを返します。 複雑な処理はすべて、このサンプルに含まれている2つのスクリプトに組み込まれたロジックで実行されるので、既存のシステムに組み込むのも簡単です。さらに例えば10階層を超えるような深さであっても、処理は高速です。
ここまでがデモの主なテーマについての、「何を」するかの話です。 このデモで示そうとした2つ目のコンセプトは、それを「どんな方法で」おこなうかです。重要な点として、数があらかじめ不定の親子関係のレコードに対して、位置構造の解析と再作成をおこなうプロセス全体が、現在のユーザがいる場所だけで完結します。つまり、レイアウトも変更せず、現在のレコードからも移動しません。(ただプロセスが終了した後に、結果を表示する目的で複製された親レコードに移動するだけです。)
この手法は「processing in place(その場処理)」と呼ばれ、従来のFileMakerスクリプトと比べて多くの利点を持っています。ですがあまり知られていないため、隠れた財宝とも言えます。実行速度の改善(ただし行う処理の内容に依存しますが)、スクリプトを単純化できること、スクリプトとインターフェース部品との依存性を削減することに加えて、processing in placeは、完全なトランザクション処理のメリットも提供します。大量のレコード複製処理の最後の方の段階でエラーが検知された場合、ただ一行「レコード/検索条件復帰(Revert Records/Requests)」コマンドだけで、レコードセット全体(どんなに深い階層でも)の作成を取り消すことができます。
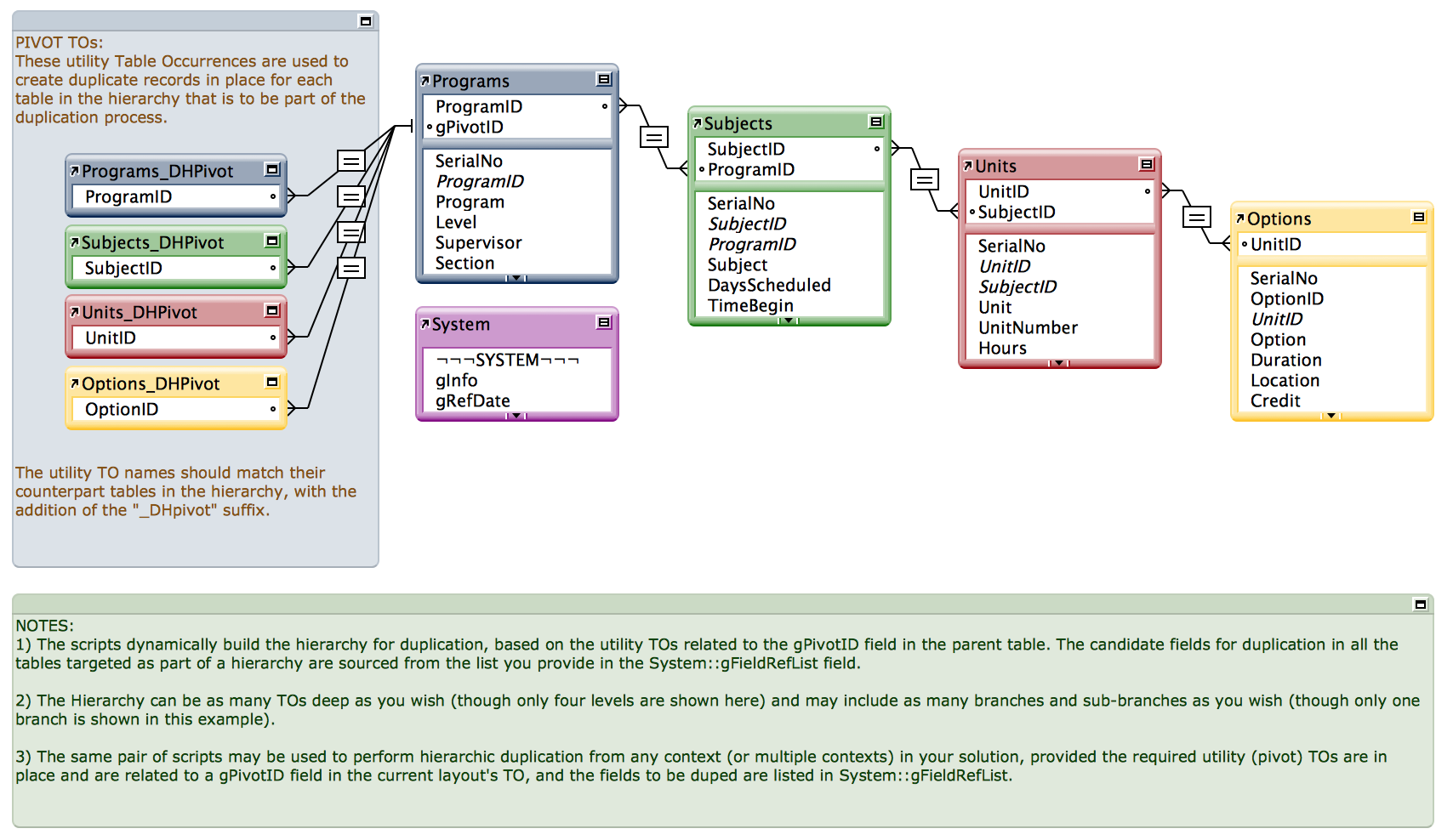
このサンプルファイルが示す3つ目のコンセプトは、モジュラー構造と移植性を兼ね備えたスクリプト設計です。グローバルフィールド(関連する各テーブルについて、どのフィールド値を複製するかを定義するため)と、標準的なリレーションシップグラフの部品(スクリプトが呼び出されるコンテキストとして)の設定は必要になりますが、スクリプトはコンテキストに依存しません。特にデータの展開を明示的には行わないので、画面レイアウトやテーブル・フィールドなどの部品を必要としません。すべてのデータの読み書きは、計算上で間接的に実行されます。
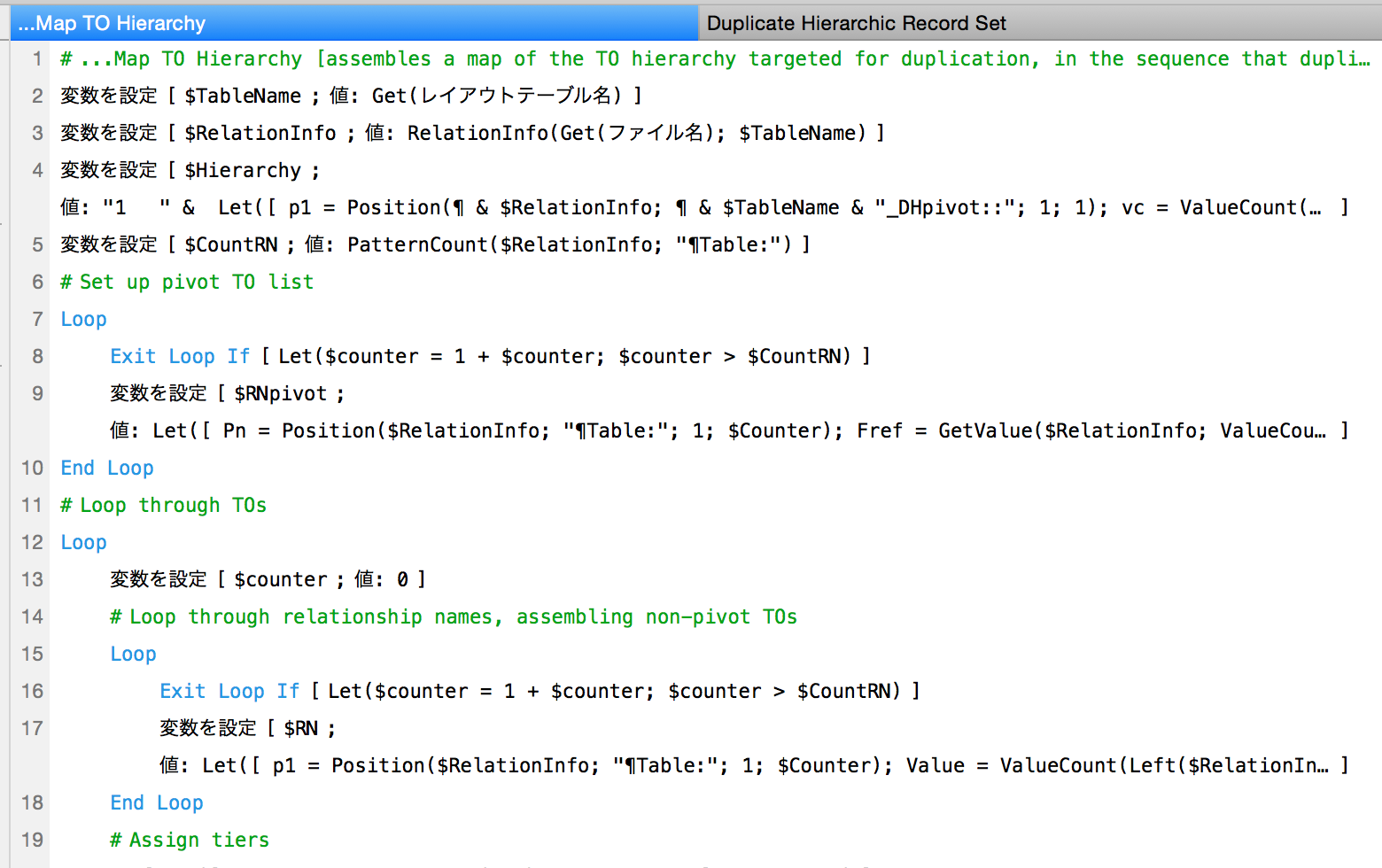
移植性に加えて、スクリプトを基本的に間接的な処理で構成していることにより、実際のタスクの範囲と複雑さと比べて、とても簡潔なコードになっています。主なスクリプトは(コメント行を除いて)わずか24行ながら、例えば数十のテーブルにわたって数百件のレコードを作成することまでできます。さらに、スクリプトに修正を加えないまま(別のソリューションに文字通りコピーするだけで)、まったく違うコンテキストでそのまま実行することも可能です。
Duplicate Hierarchy v2.0のデモファイルをダウンロード
(.zip archive)
注1:上記の.zipファイルはサポートされているすべてのプラットフォームで利用できます。
注2:デモファイルは.zipファイルから(例えば、ローカルドライブに)抽出してから開いてください。.zipファイルから直接起動した場合は、読み取り専用モードで開き意図したとおりに機能しません。
個人の使用および教育目的の場合、このデモは無料で利用いただけます。商用目的の場合はライセンスの取得が必要です。サンプルの機能を既存システムに組み込むための支援が必要な場合は、ぜひ開発者向けのサポート契約を検討ください